Working with external data: The Table Data dialogue
The Table Data dialogue is used to specify how to extract data from a file of any one of a number of formats so that it can be used in a Simile component. Its main use is for getting data for file parameters, but it also appears when creating a table function that is built into a component's equation.
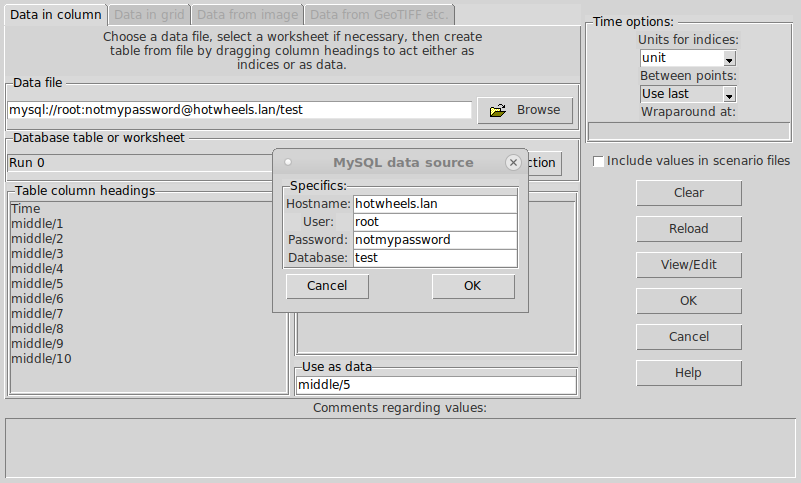
There are four tabs in the dialogue, corresponding to the four varieties of supported data format. These are:
- .csv or ODBC-compatible file, or MySQL database: data in columns
- .csv file: data in grid
- Data from image (various formats)
- Data from GeoTIFF or other GDAL-compatible file.
In addition, this dialogue also allows you to:
- View or edit data directy in a grid
- Specify interpolation and wraparound for time series
- Include raw data in scenario file.
In: Contents >> Working with external data
Working with external data : .csv file with data in column
This is the first tab in the table data dialogue. Use this method if the data for each component is in a single column in a file or database.
To select a file as the source of the data, hit the "Browse..." button and navigate to it. You can select .csv or Excel-compatible files this way. As of Simile v6.9 you can also load columns from a MySQL database. To to this, hit the "MySQL Connection" button and supply the hostname, username, password and database ID for MySQL.
If using a MySQL database or an ODBC-compatible format of file (e.g., .xls) then once you have browsed to the required file or entered the database access information, you must select the table in which the relevant data appears, using the "Database table or worksheet" pulldown menu. Once the table is selected, the column headers will be loaded into the list box below. If using a .csv file, this is not needed because the whole file is one table. When selecting the file you can also edit the character (comma by default) that separates the columns.
Storing data in a file
In order to be able to access the data, they must be stored in a certain format in the file. The file should be rectangular, consisting of a certain number of rows and a certain number of columns. The number of columns corresponds to the number of variables in the file (or, in database terms, the number of fields for each record). The file has as many records as there are units for which data were recorded, plus a single header record. The format is comma-separated values (CSV) which means that each value is separated by a comma from the preceding value. There is no comma at the end of a record. Most software packages that handle data can create files in this format.
The following is an example of a simple file containing data on the age, height and diameter of five trees:
age, height, diameter
25, 15, 0.31
32, 17, 0.37
16, 10, 0.2
19, 12, 0.23
21, 14, 0.29
Creating a new table
To create a new table using the dialogue involves several steps. The first step is to select the file from which the table data are to be taken. To do this, click the "Browse" button on the dialogue box. The file path name is then displayed in the edit box "Data file".

If you are using a more recent version of Simile (5.4 or later), you can also select a data file in an ODBC-compatible format (eg, .xls) if you have the appropriate drivers loaded on your computer. In this case you also need to select the individual table or worksheet holding your data from a pulldown menu.
After selecting the file and datasheet, the table dialogue reads and displays the column headings in a list box. The column headings are taken from the first row of the file. The rest of the file is not checked, at this stage, for speed.
One (and only one) of these headings is used to designate the data column. Drag this column heading from the list box to the edit box labelled "Use as data column". In the example file shown above, you would have the choice of "age", "height" or "diameter" and could drag any one of these to the data column edit box. The cursor changes shape while you are dragging the heading, to represent the data moving.
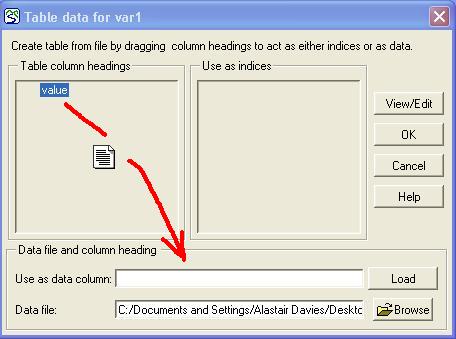
If you wish to create one or more indices to the data column, drag the heading corresponding to the desired index into the list box labelled "Use as index". To delete an index, drag the column heading from the "Use as index" list box back into the "Table column headings" list box. It is not always necessary to designate an index. If none is given, the row number is used to access each record. If indices are given, then the array returned will consist of the values from the data column indexed by the value(s) from the index column(s) in the rows where they were found. Simile v6.7p2 introduces a new feature: if one or more index columns are specified, then the single word ,line can be used in place of a data column header, and this means that the data in the array will be the line numbers where each index value or combination of index values were found. For instance if the table at the bottom of this page were loaded with the index column headers Y index and X index (in that order!) and the data column header ,line then the first row of the resulting matrix would have the values 1,4,7, these being the rows where the y index of 1 was found, sorted by X index.
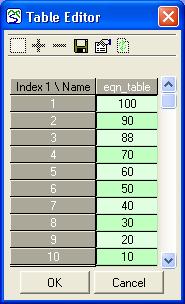
You can view the data you have loaded in a separate window. To do this, click the View/Edit button. You can make changes to the data in this window, and click OK to accept the changes or Cancel to abandon them. You can also save the data to a file. Note that if you extracted the data from a file containing more than one variable, you should not save the extracted data to the same file, or you will lose the other variables.
Editing an existing table
If a table already exists for the component, you will not need to follow the above steps again. If you wish to see or change the data in the table, you can click the View/Edit button. This will present you with the Table Editor, as above. If you wish to extract data from a different file, you can use the Browse button, as above, to begin as if creating a new table. If the data in the file have changed since the table was created, you can use the Load button, to extract the new data using the same specification of column heading and indices. (If the file is not present, perhaps because you are working on a different machine from where the model was created, clicking the load button will give an error.)
Final notes
When preparing to use multiple indices, it is often best to arrange the index columns in the data file in a logical sequence, for example as follows:
| X index | Y index | Height | Diameter |
| 1 | 1 |
12.3 |
1.3 |
| 1 | 2 |
12.7 |
1.2 |
| 1 | 3 |
13.1 |
0.9 |
| 2 | 1 |
11.8 |
1.5 |
| 2 | 2 |
12.3 |
1.4 |
| 2 | 3 |
11.7 |
0.9 |
| 3 | 1 |
13.5 |
1.0 |
| 3 | 2 |
12.1 |
1.1 |
| 3 | 3 |
13.0 |
1.1 |
For this file, two indices would be selected, the x- and y-values, together with one data column, either the height or the width. If both were needed, it would be necessary to have two variables, and to create a table in each one that each used one of these columns. The indices systematically provide values for a three-by-three grid. This makes it easy to extract the data using the first of the techniques outlined above.
In: Contents >> Working with external data >> The table data dialogue
Working with external data : .csv file with data in grid
If you have a .csv file with a 2-dimensional grid of data items, this can be loaded directly into a 2-dimensional array file parameter in Simile. For other 2-D formats that can be read into a spreadsheet, you can create the .csv file.
To use this file, go to the second tab in the table data dialogue. Here, you can browse to the file containing your data. When selecting the file you can also edit the character (comma by default) that separates the columns. Once you have done that, the four entry fields below will be filled, with "Finish at row" and "Finish at column" containing the number of rows and columns respectively in the file.
You can change the values in these fields in order to read only a part of the grid of values. This is most likely to be needed if the file contains headers that are not actually part of the data. For instance if the first row of the file contains headers, you specify "Start at row: 2" to avoid reading these into the table. You can use the View/Edit function to look at the data that will be read, and adjust the start row and column until it shows the data you want. Whatever values these have, the first row and column that is actually read will have index 1 in the data table (or 0 if it is a time series).
As of Simile 5.4 there are some extra features in this pane: the 'transpose' checkbutton causes the outer indices to correspond to the columns, rather than the rows. Also you can reverse the bounds, i.e., put a higher number in the "Start at..." than the "Finish at..." entries. This has the effect that the same part of the file will be read, but in the opposite order; the last row or column will contain the data items for index 1.
As of Simile v5.5 there is also the option to use fields from the grid as indices as well as data. This is analogous to the way index columns can be specified when reading data from columns, and is useful when the indices need to be enumerated type members. Below the entries for the start and finish rows and columns, there are pull-down menus to choose the source of the indices. By default these are set to "Position in data area", which causes the indices to be generated as described above. The row indices can also be got from "First column in grid" (i.e., leftmost column), or "Column to left of data". If either of these are selected, the index for each row will be the item in that row and the specified column. Note that you cannot choose these options if the data area starts at column 1, and if it starts at column 2 then they both do the same thing, i.e., get the index item from column 1. There are a similar set of options for getting the column indices from a row outside the data area.
In: Contents >> Working with external data >> The table data dialogue
Working with external data : Data from image
Simile can extract a 2-dimensional array of data from an image file, with each pixel in the image corresponding to a datapoint. The image can be in any format supported by the Tkimg package, which is to say, most of them.
To get image data, use the third tab in the table data dialogue. The upper panel on this tab is much the same as on the data in grid tab, and does much the same thing; you browse to the file, and select the positions in the image at which to start and finish reading data if you do not want the whole thing.As in the case of a data grid, you can reverse each axis or transpose the axes.

The unique bit is the bottom panel, Values for Colours, by which you can instruct how each colour in the image is to be converted into a value in the data array. "Value for black" and "Value for white" specify the endpoints of the range of values. For other colours, in general the lighter it is, the further from "black" and the closer to "white" the corresponding value will be. There is a pulldown menu with a choice of methods for getting values from other colours; "use luminosity" averages the intensity of red, green and blue, or you can use any of these levels on their own. For instance, an area of pure magenta will give the same value as white if using red or blue levels, and the same value as black if using green level. If using luminosity the value for magenta will be (2*white+black)/3. You can also select "use 8-bit colourmap" which just assigns a unique value to each colour in an 8-bit coloured image, the intention being that these same values are also available to set the colour legend in the grid helper, allowing a version of the image to be reproduced.
Finally there is a field to enter a value which will be used where the image is transparent (clear). You only need to enter a value here if your image has some transparent areas. This value can be outside the range from black to white.
In: Contents >> Working with external data >> The table data dialogue
Working with external data : Data from GeoTIFF or similar
GeoTIFF is a file format which is based on the TIFF image, but which is not actually an image and cannot be displayed in most image viewers. It differs from an image file in that:
- It also contains georeferencing data, and
- The image data can be in a number of formats including floating-point.
Simile uses GDAL (Georeferencing Data Abstraction Library) to read GeoTIFFs and other similar data files and convert them into 2-D arrays of parameter values. This library is not distributed with Simile, but it is Free Software; you must go and find it on the Web, and install it on your computer before you can use this feature of Simile. A version of GDAL is included in most Linux distributions and can be installed via the package manager. When it is installed, Simile can also create GeoTIFFs using the grid helper.
Havng done this, the procedure for reading data from a GeoTIFF is much the same as for a grid of values in a .csv file. The actual values in the file are used in the data array without any conversion; the assumption being that since they can be floating-point, whoever created the dataset would have been able to include physically meaningful values.
Because getting data from this type of file is a low-level operation, it is much faster than the other options for loading data from files where very large arrays are involved. However the price for this is the loss of the "transpose" and reverse ordering options.
In: Contents >> Working with external data >> The table data dialogue
Working with external data : View/edit as table
Once you are in the table data dialogue, you can hit the View/Edit button to bring up a version of the table helper to display your data and, if necessary, edit it. The data need not have come from a file; it might just have been typed into the entry field of the file parameters dialogue. However it will not work if the data has been loaded as raw data from the scenario file.
This tool has all the features of the table helper, i.e., you can arrange the different index and time point headings vertically or horizontally, and you can save the displayed data as a .csv file. It also allows you to edit the data, either by typing values into individual fields or by cutting and pasting a grid of values into the grid. For example, a quick way to transpose a square array: Put outer indices on rows and inner ones on columns, then cut all the data, then put inner indices on rows and outer ones on columns and paste it back in.
The main use of this tool though is to check after reading data from a file, using whatever method, that you have actually picked up the data you intended to get.
In: Contents >> Working with external data >> The table data dialogue
Working with external data : Time series
In the section on time series formats, we saw that the series includes special time points and special values to specify what what values to use away from the actual data points. If you are using one of the mechanisms provided by the table data dialogue to get your data, you do not have the opportunity to include these special points (unless they happen to be in your .csv file, and if they are, they work fine). But you can get the same effect by including them with the tools in the 'other times' panel in the top right corner. These are only available if providing values for a variable parameter when running the model.
The pulldown menu for "Between points" allows you to select from three options which have the same effect as the special values for the time point OTHERS: "use_last", "use_closest" and "interpolate". The entry for "Wraparound at" has the same effect as the time point given for the special value "restart".
There is also an entry field to set the units for your time series indices as described for the INTERVAL point.
In: Help >> Working with external data >> The Table Data dialogue
Working with external data : Raw data in scenario file
Normally, the scenario file contains only references to data files, with information as to how the data is to be extracted. However, if you type the data straight into the entry field in the file parameter dialogue, or edit it with the table editor from the table data dialogue, the resulting data no longer corresponds to anything that can be got from a data file, so instead the data is stored directly in the scenario file. This is usually a bad thing, because the XML format used is unwieldy and verbose, and it may take a long time to load or save. But keeping references in the scenario file also has disadvantages, chiefly:
-
When publishing a model with a scenario file like this, the file itself must be included along with all the other files referenced by it, and these must be installed in the same place in the directory tree relative to the scenario file as they were when the scenario was created
-
The process of loading values from a .csv file is quite time consuming, as the file has to be parsed and checked for syntax errors before the ASCII numerals can be converted into their actual values, and this has to be done every time the data is loaded.
So we came up with a way to maximize convenience, and added a checkbox to the table data dialogue captioned "Include values in scenario files". If you check this, then when you save a scenario file including the parameter in question, it will include all the data for that parameter even if it is also available in the datafile. Furthermore, instead of it all being in longhand XML, it will be in raw binary format, base64-encoded into Ascii and stuffed into a CDATA field.
This means it is small. And fast. If the model uses a lot of data that isn't going to change from one scenario to the next, this is the best way of handling it. There is a slight downside; the values are unpacked and loaded directly into the model's data structures, and are never converted into the TclTk format that allows them to be displayed as text (except for a few at the start and end, to display in the file parameter dialogue, and these give you just the raw numbers if using booleans or enumerated types). So you cannot look at them or change them with the table editor -- but that gets a bit difficult with very large arrays anyway. The only way to change them is to load them once more from a datafile.
In: Contents >> Working with external data >> The table data dialogue