How to add a submodel symbol:
See Adding Submodels
A submodel is first and foremost a way of grouping together a number of other model elements, including other submodels. This is done by either drawing a  submodel envelope around a number of elements in the model diagram, or by creating an empty submodel and inserting model elements into it.
submodel envelope around a number of elements in the model diagram, or by creating an empty submodel and inserting model elements into it.
However, the reasons for wanting to do this are many and varied, and it is important to appreciate that the submodel construct can be used for a range of modelling needs. There are considerable benefits to using a single method to fulfil this range of needs, both in reducing what you need to learn, and keeping the resulting models simple and flexible.
This section overviews the different uses of the submodel construct, and the different types of submodel that you can have. Other sections provide more detail on particular topics.
Using a submodel to show the main components of a complex model
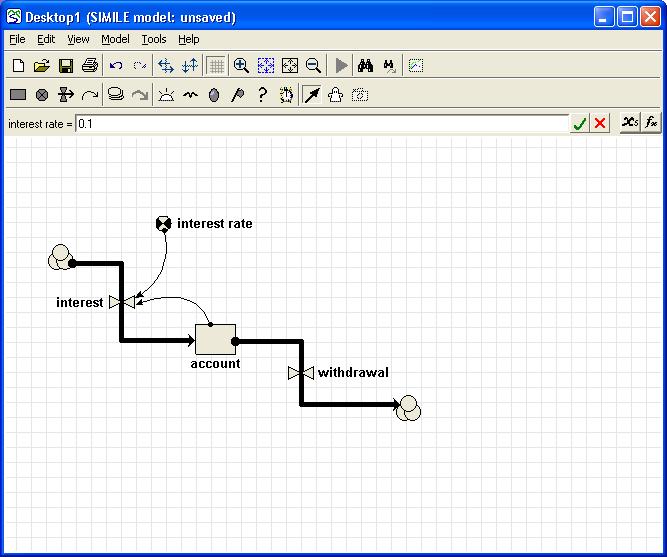
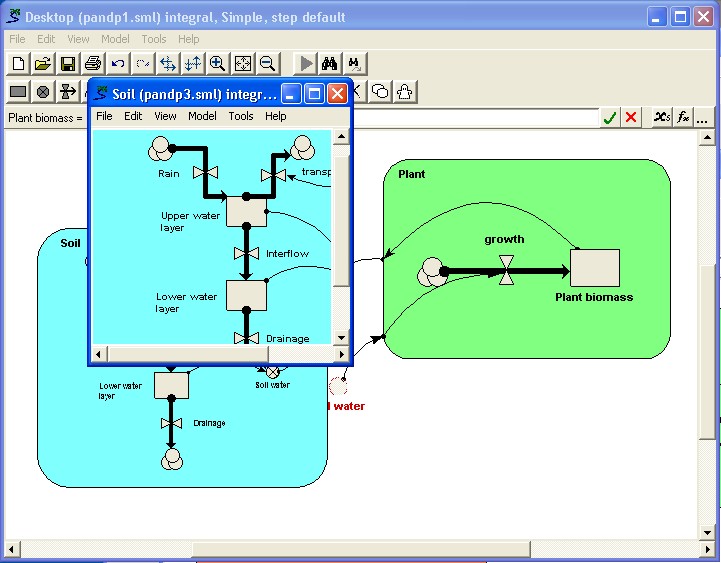
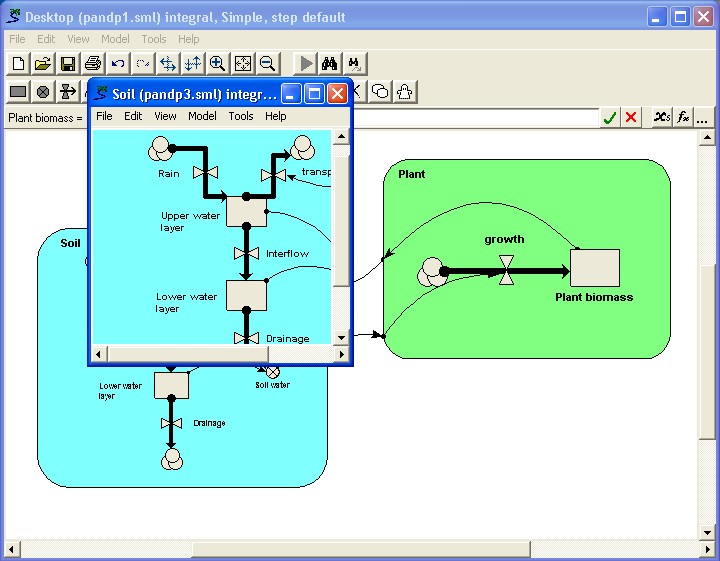
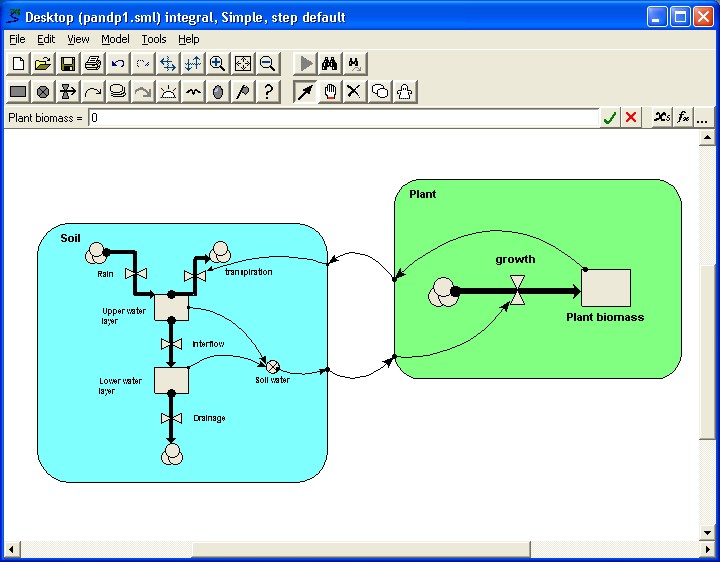
You have constructed a model with a number of compartments and flows. Some relate to vegetation; some to the animals in the area; some to soil water and nutrients. By grouping the model-diagram elements for these different parts into submodels (called "Vegetation", "Animals" and "Soil"), the gross structure of the model is immediately apparent.
Conversely, you may prefer to design a model in a top-down fashion. Starting with a blank screen, you can rapidly add submodels corresponding to the main components of a proposed model, then subsequently add the various compartments, flows etc inside these.
Using a submodel for multiple views on a model, perhaps at different scales
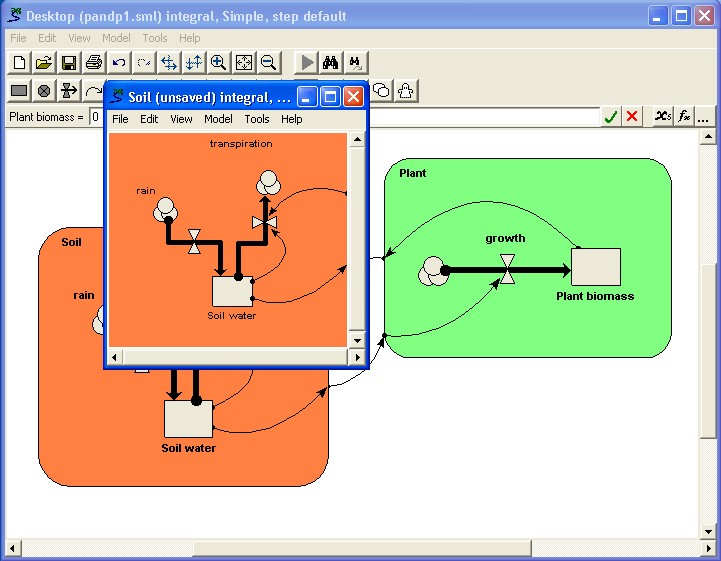
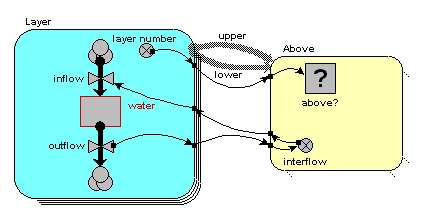
Once part of a model is made into a submodel, you can open a separate window for it (by double-clicking on its boundary with the  pointer). This window can be kept on the screen while you scroll the main model diagram to some other part of the model. Also, you can change the zoom factor for each main model window or submodel window separately, enabling you to see part of the model in fine detail while maintaining an overview of the whole model at a coarser scale.
pointer). This window can be kept on the screen while you scroll the main model diagram to some other part of the model. Also, you can change the zoom factor for each main model window or submodel window separately, enabling you to see part of the model in fine detail while maintaining an overview of the whole model at a coarser scale.
Using a submodel to make a part of a model into a stand-alone model
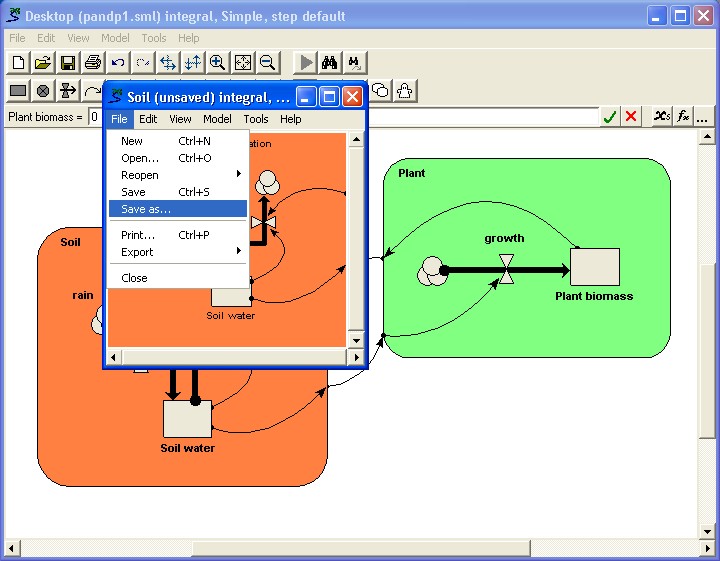
For the model described above, you may want to see how the vegetation part behaves, assuming fixed inputs from the animal and soil sections that affect it. You draw a submodel envelope around the vegetation, open up a separate window for it, then use the File: Save command to save it to a file. You can then start up Simile again, and load just the saved vegetation submodel (which is now a model in its own right). You can now explore how it behaves by itself. This can be very useful for testing and debugging purposes.
Using a submodel for modular modelling: swapping one module for another
For many years, the battle cry of those fed up with the implementation of models in computer programs was "modular modelling!". If we had a modular modelling system, it was argued, then models could be easily constructed from a number of pre-programmed modules, and the effectiveness of the community as a whole would be greatly increased by the sharing of these modules, avoiding huge duplications of effort.
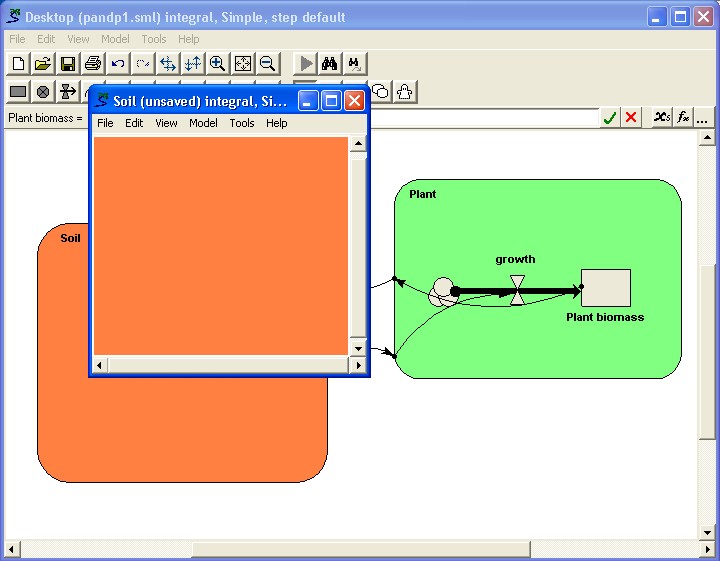
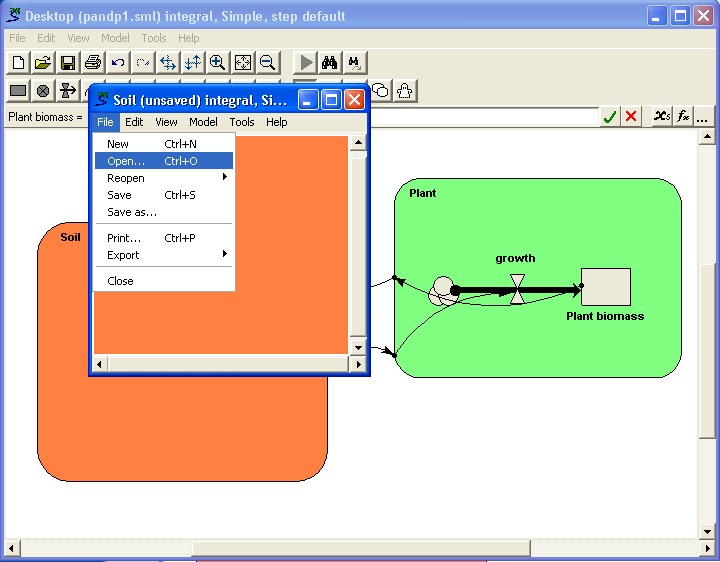
The submodel concept in Simile supports modular modelling. You can open up a separate window for a submodel (say, a vegetation submodel); clear the contents of the submodel (by doing File: New), then load a different vegetation model into the submodel window. Influence links with the rest of the model can then be made one by one.
Furthermore, Simile supports plug-and-play modularity (which is what is normally meant by "modular modelling"). If two or more vegetation submodels have been designed to share a common set of influences (in and out) with the rest of the model, then the information about this interfacing can be stored in a file (an interface specification file). When you next load one of the submodels from a file, you simply refer to the interface specification file, and all the influence links are made in one quick operation.
Using a submodel for disaggregation;
or (conversely) specifying a fixed number of objects of a certain class
These two terms are lumped together because they are the same concept, seen from opposite perspectives. You can disaggregate an area into a number of patches; or you can think in terms of one patch, then have multiple patches to represent some larger area. The end result in both cases is exactly the same.
Once you have made a submodel you can specify (by going to its Properties dialogue box) that it is a "fixed-membership submodel", and specify a number of instances. In the "Control of number of instances" panel, select the "Using specified dimensions" radio button and enter the number you require. The submodel then represents each of that number of instances. Visually, it now appears different, because it now has multiple lines on the right- and bottom-edges: like a stack of cards. Internally, Simile now handles each instance separately: each can have its own parameter and initial values, while they all have the same compartments, flows etc.
This enables many forms of disaggregation to be captured. For example:
- disaggregating a population into age, size, or sex classes;
- disaggregating a vegetation component into the several species that make it up;
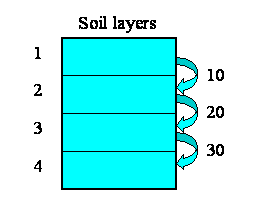
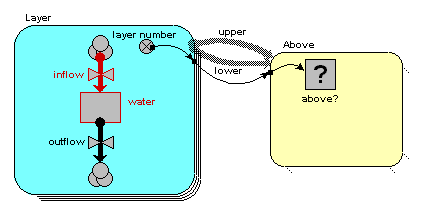
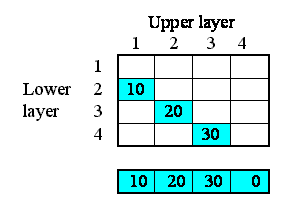
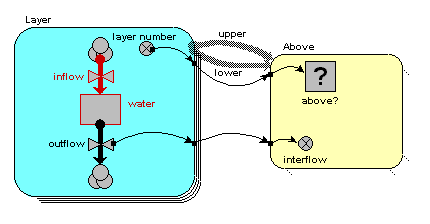
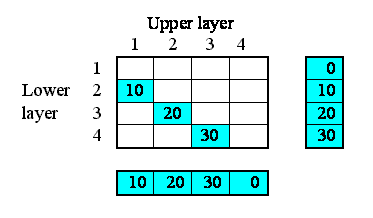
- disaggregating soil or forest canopy into a number of layers;
- disaggregating space into grid squares, polygons, or some other form of spatial unit.
Note that there are two further options in the pull-down menu: rectangular grid and hexagonal grid. These also correspond to fixed-membership submodels, but make special functions available within the submodel for capturing various properties of rectangular/hexagonal grids.
Using a submodel to specify a dynamically-varying population of objects
The modelling world divides into those whose models are based on differential/difference equations (with or without disaggregation); and those who subscribe to an approach based on collections of objects (variously called object-oriented, individual-based or agent-based modelling).
Simile enables a population approach to be combined with a differential-difference equation approach. For example, a modeller might represent the vegetation in terms of compartments and flows, while the herbivores might be represented as individual animals, which are created, grow and die. In order to do this, a submodel is specified as being a population submodel (Specify control of number of instances as "using population symbols" in its Properties dialogue box), and model elements can be added for specifying the initial number, and the rules for the creation of new individuals and the elimination of those already n the population. Visually, the submodel now appears with a shadow line for the top- and left-edges, and another for the bottom- and right-edges.
The remaining option for controlling instance numbers is "Using number of data records in file". This will set the number of instances according to the number of values provided for fixed parameters within that submodel, so the same model can be used for simulations involving datasets of different sizes.
Using a submodel to specify the conditional existence of some part of the model
When a model is implemented in a conventional programming language, large chunks of the program can be enclosed inside an if … end if block: i.e. whether it is actually evaluated depends on some condition. This programming device may be applied to several different purposes:
- You may want to have several alternative ways of modelling some part of the system (e.g. a growth function), only one of which is active in any one run of the model. A flag determines which one is active.
- You may want to model a set of species using a single submodel, but with only some species present in any one run of the model.
- You may want to model a number of spatial patches, some of which contain one land use type, and others of which contain another. You need to include a submodel for each one within the multiple-instance patch submodel - but switch one or the other on in a particular patch.
All these situations can be handled in Simile using a conditional submodel. This is simply a submodel, either simple or fixed-membership, but with a condition symbol added. Visually, we can tell that it's a conditional submodel both by the presence of the condition symbol, and by a set of dots going down diagonally to the right from the submodel envelope. The condition contains a Boolean expression: if this evaluates to "true", then the submodel (or an instance of it) exists; if not, then it doesn't.
A conditional submodel will, like any other, have influences coming out from the model elements it contains. However, the number of values passed along each influence could be anything from zero (if no instances of the model exist) to the number given in the fixed-membership specification (if they all do). It is thus a variable-size data structure: in other words, a list (with the name of the variable enclosed in curly braces {…} ). In Simile, the only thing that can be done with a list is to evaluate it: usually, to sum its values. If the list is empty, then the sum is zero. If the list contains a single element, then the sum is whatever this value is.
Using a submodel to specify an association between objects
Once our modelling language allows us to think in terms of multiple objects of a certain type, then it is frequently the case that we start to recognise relationships between objects. These relationships may be:
- between objects of the same type: one tree shades another; one grid square is next to another; one person is married to another; or
- between objects of one type and objects of another: one farmer owns a field; one field is close to a village.
Since Simile is a visual modelling language, and since such relationships are an important aspect of the design of a particular model, Simile provides visual elements to show diagramatically such relationships between objects. Unfortunately, the term "relationship" is normally used in ecological modelling to refer to a relationship between variables (as opposed to objects), so we use the term "association" instead. This is the same term used in UML (the Unified Modelling Language, the standard object-oriented design language used in the software-engineering community).
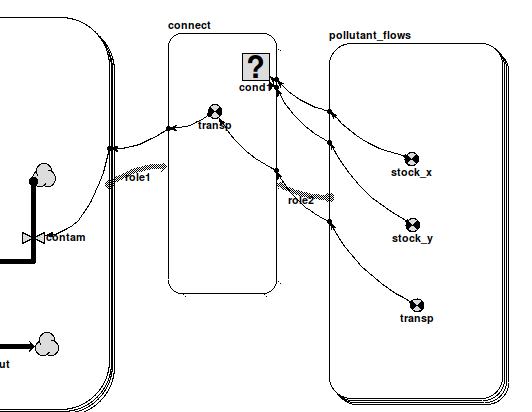
An association can itself have properties. We can, for example, have a variable representing the actual distance between a field and a village: this is a property of neither the field or the village, but of the association between them. In Simile, the submodel is the construct that is able to hold a number of quantities, therefore we use a submodel to represent an association: it is then called an association submodel.
However, such a submodel is simply a normal Simile submodel. It becomes an association submodel by virtue of being linked to the submodel (or submodels) representing the objects that have the association. The linking is done using role arrows: one role arrow is drawn for each type of object that participates in the association. Thus:
- for the owns association between farmer and field, we draw a single role arrow from the farmer submodel to the owns association submodel, and one from the field submodel to the owns association submodel;
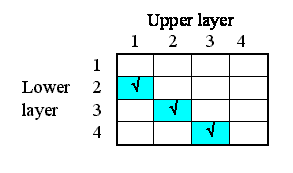
- for the next to association between one grid square and another, we draw two role arrows from the grid square submodel to the next to association submodel: one role arrow represents the field under consideration, while the other represents its neighbour.
Using a submodel to specify a satellite relationship between one object and another
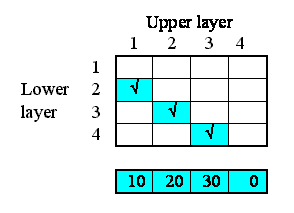
Let's say that you have a multiple-instance submodel containing information on the species and volume of a set of individual trees: each instance is one tree. You would like to find the total volume of all trees belong to species 1.
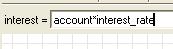
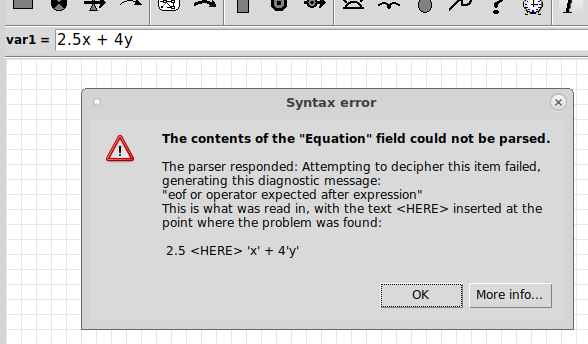
This is easy to do if you have model the trees using a fixed-membership submodel (i.e. assuming that you have a fixed number of trees). You simply take influence arrows from the species and volume variables inside the submodel to a variable outside (say total), and give total the equation:
total = sum(if [species]==1 then [volume] else 0)
[species] and [volume] are both arrays with the same number of elements, and Simile's array language matches them up.
This technique will also work if you use a population submodel to model the trees. But suppose you want to do several operations on only the trees of a particular species? Rather than apply the species condition each time, you can make a satellite submodel corresponding just to the individuals you are interested in. It would involve creating a new submodel for the species 1 trees, using a single role arrow from the tree submodel to this satellite submodel, and entering the condition "species==1". An instance of this submodel will be created for each tree of species 1, and not for the others. If you then take the "volume" value into the submodel, then you can extract the volumes just for species 1.
A satellite model with the appropriate condition can represent any subgroup of the instances in its base model, including cases where instances may become members or stop being members of the subgroup as the model runs.
Using a submodel to specify different time bases for different parts of a model
By default, Simile uses the same time step to update all the model state variables. However, if you are modelling a system containing trees and crops, then you might very well want to model the trees on an annual basis (time step of one year), and the growth of the crop on a weekly basis (time step of 1 week).
Simile enables you to specify a time step category for any submodel. For each new time step category that you request, Simile adds an extra Update every entry in the Run Control dialogue window, and that is where you specify the actual time step (e.g. 0.01) to be used for each category.
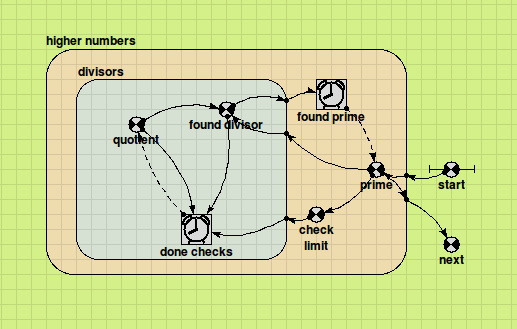
Using a submodel to allow iterative calculation of a function
Some calculations simply cannot be done within the system-dynamics paradigm, as they involve actions that are repeated until some indication of completion is achieved -- for instance, methods involving successive approximation.
These can be included in a Simile model by creating a submodel for the iterative calculation, and including an alarm symbol. This is a boolean valued component, and will cause all the variables in the submodel to evaluate repeatedly until it evaluates to 'true'. If the iteration involves values from the previous calculation step, these can be referenced using an influence arrow with the "Use values made in same time step" property.
In: Contents >> Graphical Modelling >> Object/agent based
 You start Simile by double-clicking on the desktop icon created during installation, or by clicking on the Simile icon in the Start Menu.
You start Simile by double-clicking on the desktop icon created during installation, or by clicking on the Simile icon in the Start Menu. compartment symbol in the toolbar.
compartment symbol in the toolbar.

 flow symbol in the toolbar.
flow symbol in the toolbar.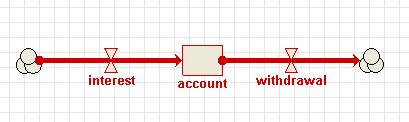
 variable symbol in the toolbar.
variable symbol in the toolbar.
 influence arrow button in the toolbar.
influence arrow button in the toolbar.
 pointer button in the toolbar.
pointer button in the toolbar.
 pointer button in the toolbar.
pointer button in the toolbar.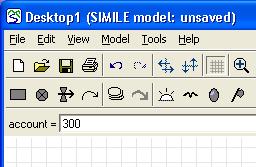
 green tick mark or press the Return key.
green tick mark or press the Return key.



 Compartment
Compartment
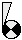 Parameter (a coefficient in an equation): e.g. the reproductive rate per individual animal. Could also be a site constant: e.g. elevation above sea level. Its value will remain constant throughout a simulation run.
Parameter (a coefficient in an equation): e.g. the reproductive rate per individual animal. Could also be a site constant: e.g. elevation above sea level. Its value will remain constant throughout a simulation run. Input lever: a
Input lever: a  Calculation order
Calculation order




 Limit event : This represents an event that occurs when a model value reaches some pre-set limit. It requires an equation and a minimum and/or maximum value to be entered. The event occurs when the value of the equation reaches the minimum or maximum, and the event should cause the value to go no further in that direction. The event is boolean (i.e., has no magnitude) if only one limit is present. If both are present its magnitude is -1 at the lower limit and 1 at the upper limit. Hence its equation does not affect its magnitude, only its time of occurrence.
Limit event : This represents an event that occurs when a model value reaches some pre-set limit. It requires an equation and a minimum and/or maximum value to be entered. The event occurs when the value of the equation reaches the minimum or maximum, and the event should cause the value to go no further in that direction. The event is boolean (i.e., has no magnitude) if only one limit is present. If both are present its magnitude is -1 at the lower limit and 1 at the upper limit. Hence its equation does not affect its magnitude, only its time of occurrence.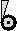 Time series: This gets its values from outside the model like a
Time series: This gets its values from outside the model like a  'zap' button.
'zap' button. Single role arrow
Single role arrow
 condition symbol
condition symbol Two role arrows from different submodels
Two role arrows from different submodels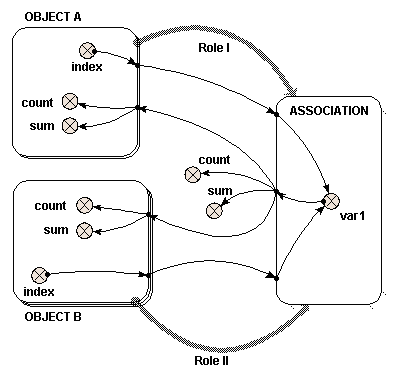
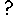 condition symbol
condition symbol Two role arrows from the same submodel
Two role arrows from the same submodel
 condition symbol
condition symbol
 Iteration
Iteration













 variable
variable compartment
compartment image element also behave as node-type elements, though no node is associated with them. The following procedure is used to add node-type elements.
image element also behave as node-type elements, though no node is associated with them. The following procedure is used to add node-type elements.
 submodel symbol in the tool bar.
submodel symbol in the tool bar. Duplicating elements
Duplicating elements pointer tool on the tool bar.
pointer tool on the tool bar. copy and
copy and  paste commands.
paste commands. Moving model diagram elements around
Moving model diagram elements around pointer tool if not already selected.
pointer tool if not already selected. Moving flow or squirt valve symbols
Moving flow or squirt valve symbols Moving influence arrows
Moving influence arrows
 move tool, when applied to submodels.
move tool, when applied to submodels. Deleting elements from the model diagram
Deleting elements from the model diagram pointer tool of not already using it.
pointer tool of not already using it.
 select tool on the toolbar.
select tool on the toolbar. Compartments
Compartments Flows
Flows Simple submodels
Simple submodels Role arrow
Role arrow Creating ghost elements
Creating ghost elements
 "Find" calls up a dialogue box into which you enter the text, and specify which text elements to search
"Find" calls up a dialogue box into which you enter the text, and specify which text elements to search "Find Next" searches for successive occurrences of variables satisfying your search criterion
"Find Next" searches for successive occurrences of variables satisfying your search criterion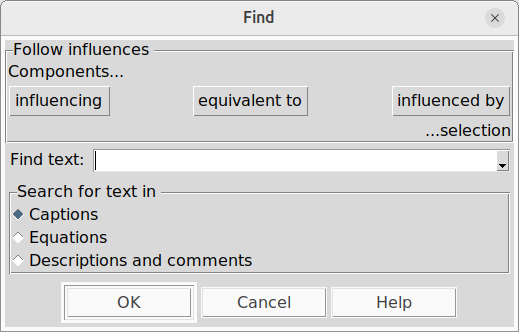
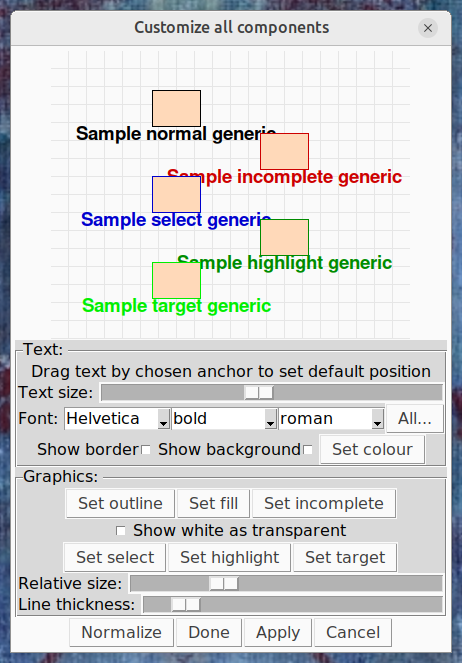
 select tool to double-click within a blank area, within the submodel if you have added one, or if not, anywhere on the desktop. This invokes the
select tool to double-click within a blank area, within the submodel if you have added one, or if not, anywhere on the desktop. This invokes the  pointer mode, holding the pointer over any model component will cause a popup window to appear including that component's equation, value(s) (while the model is running) and description and comments. These can be suppressed by unchecking any or all of these options. If none is selected, the popups are suppressed completely.
pointer mode, holding the pointer over any model component will cause a popup window to appear including that component's equation, value(s) (while the model is running) and description and comments. These can be suppressed by unchecking any or all of these options. If none is selected, the popups are suppressed completely.
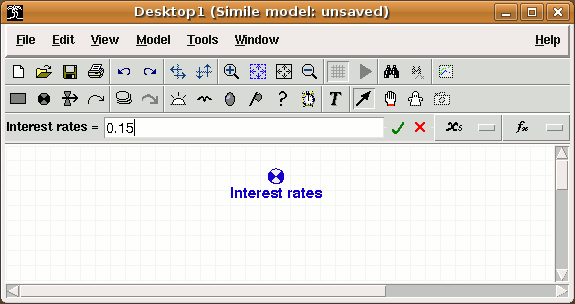
 button, or hit return, to set the equation.
button, or hit return, to set the equation. button if you make a mistake. It restores the previous entry.
button if you make a mistake. It restores the previous entry. button.
button.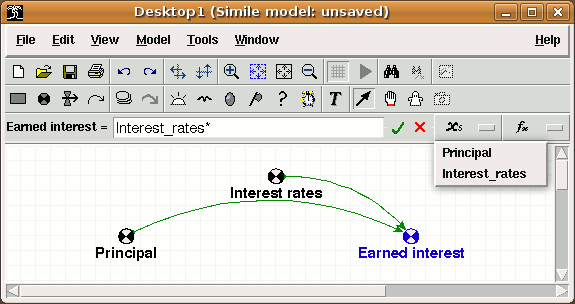
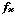 button. The top level of this cascade also contains an entry labelled "Enum. type constants", for adding the names and members of any
button. The top level of this cascade also contains an entry labelled "Enum. type constants", for adding the names and members of any 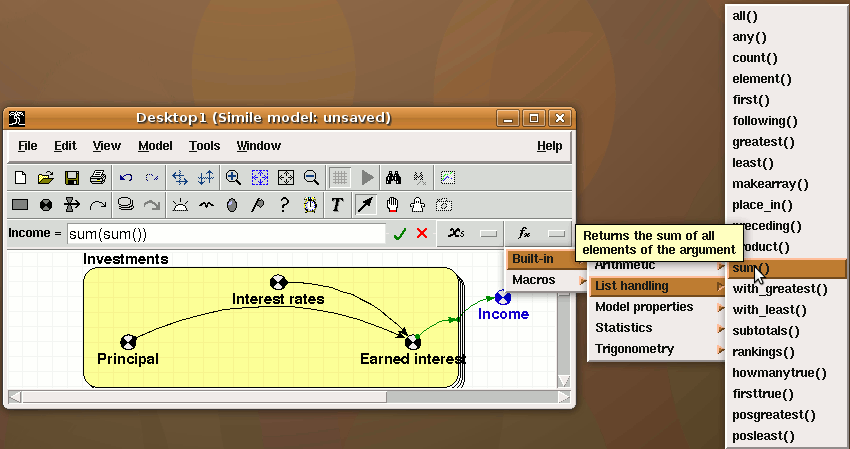



 pull-down menu button on the
pull-down menu button on the 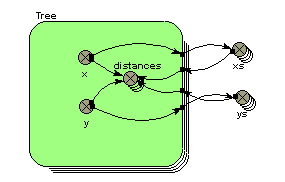
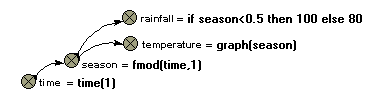




 Array-valued components
Array-valued components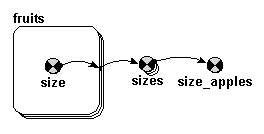

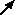 select mode, or by using the "Properties" command of the
select mode, or by using the "Properties" command of the 

 creation,
creation,  reproduction,
reproduction,  immigration and
immigration and  extermination.
extermination.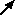 Pointer tool, then double-clicking anywhere in the blank area of the submodel (not on its border, and not on any existing elements). Note that the "Generated set" radio button has been selected by default. This term denotes that the submodel is to be fixed-membership. Enter a value into the "Dimensions" box corresponding to the number of instances you want. Click on the "OK" button.
Pointer tool, then double-clicking anywhere in the blank area of the submodel (not on its border, and not on any existing elements). Note that the "Generated set" radio button has been selected by default. This term denotes that the submodel is to be fixed-membership. Enter a value into the "Dimensions" box corresponding to the number of instances you want. Click on the "OK" button. Pointer tool, then double-clicking anywhere in the blank area of the submodel (not on its border, and not on any existing elements). Click on the "Population" radio button. Do not enter a value into the "Dimensions" box. You can use the Creation symbol to specify the initial number of individuals in the population. Click on the "OK" button.
Pointer tool, then double-clicking anywhere in the blank area of the submodel (not on its border, and not on any existing elements). Click on the "Population" radio button. Do not enter a value into the "Dimensions" box. You can use the Creation symbol to specify the initial number of individuals in the population. Click on the "OK" button.





 the
the  the
the  the
the  save button on the tool bar.
save button on the tool bar. open button on the tool bar.
open button on the tool bar. new configuration can be selected, to remove all the currently displayed helpers.
new configuration can be selected, to remove all the currently displayed helpers.







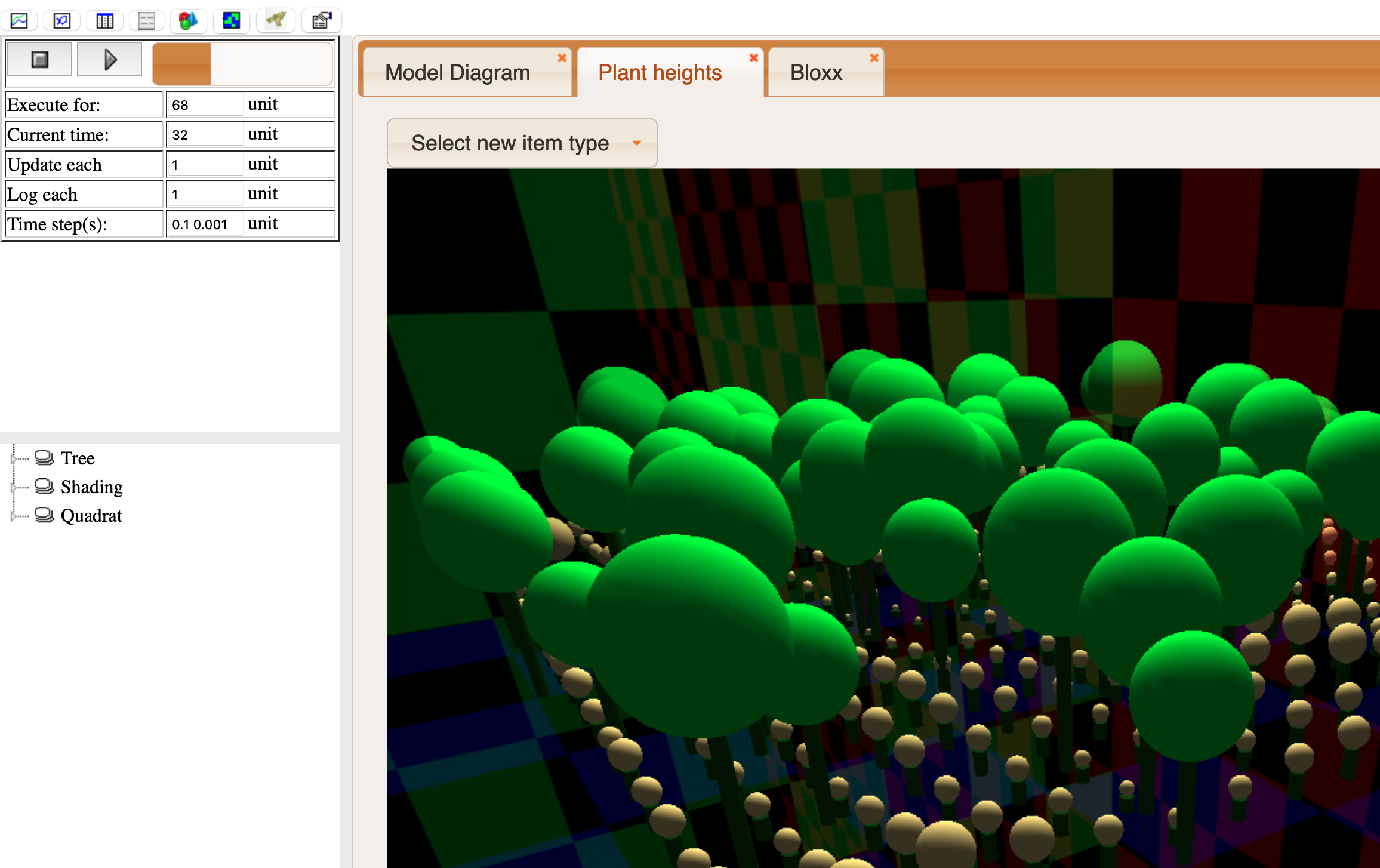
 play button will begin execution at the current time for a number of time steps set using "Execute for".
play button will begin execution at the current time for a number of time steps set using "Execute for". stop button will stop the simulation (if one is running) and set the current time to zero.
stop button will stop the simulation (if one is running) and set the current time to zero. pause button will pause the simulation at the current time.
pause button will pause the simulation at the current time. Black
Black Purple
Purple Yellow
Yellow Green
Green Blue
Blue Red
Red Grey
Grey White
White Using the
Using the  Using the
Using the 
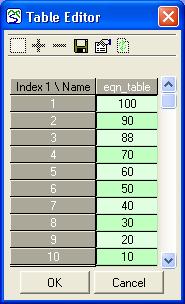
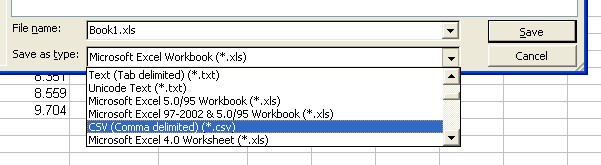
 Saving table data
Saving table data


 add button to add a slider for a model component if it is a fixed or variable parameter. The - button allows you to remove the slider for a particular model component. The
add button to add a slider for a model component if it is a fixed or variable parameter. The - button allows you to remove the slider for a particular model component. The  "add all variables" button will add sliders for all model components marked as variable parameters, as it is for these that sliders are most usually required. The Clear button will remove all sliders. Sliders are grouped by submodel, if their variables are in different submodels.
"add all variables" button will add sliders for all model components marked as variable parameters, as it is for these that sliders are most usually required. The Clear button will remove all sliders. Sliders are grouped by submodel, if their variables are in different submodels.

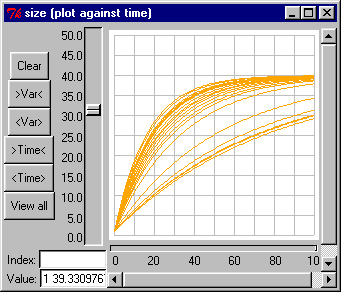

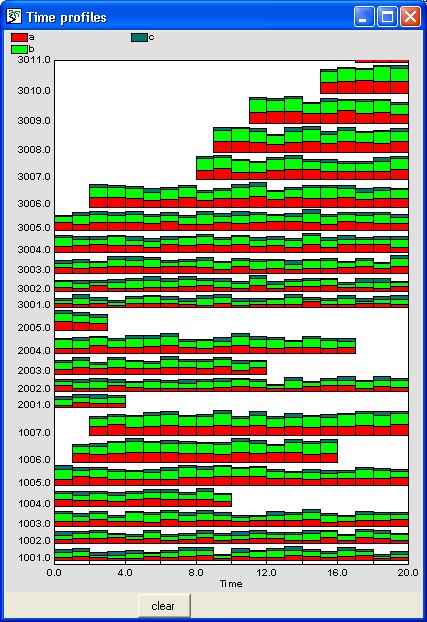

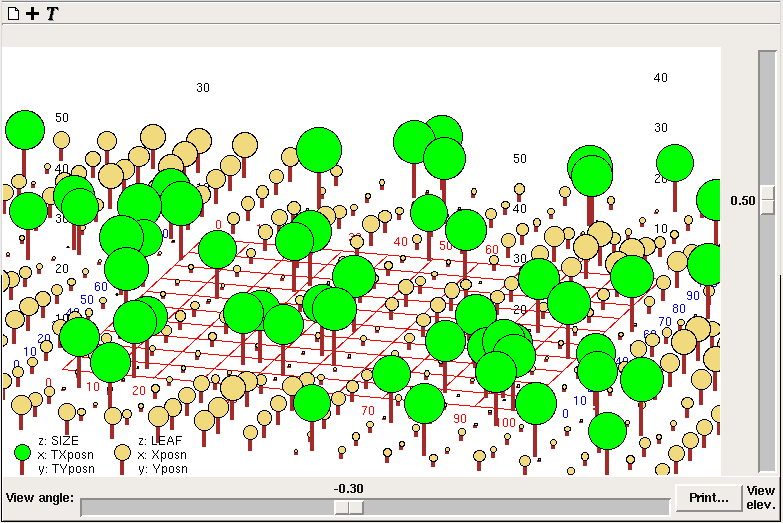

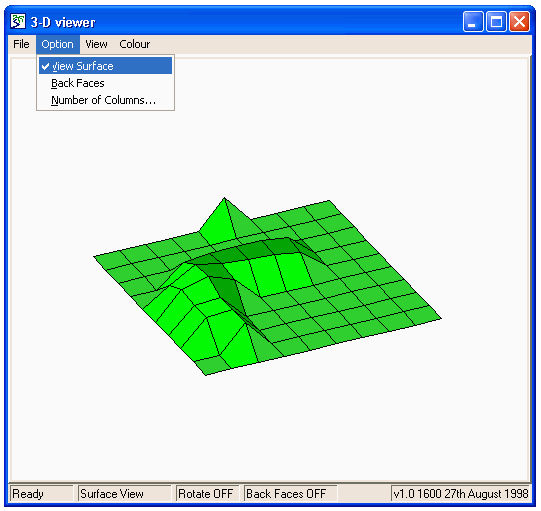
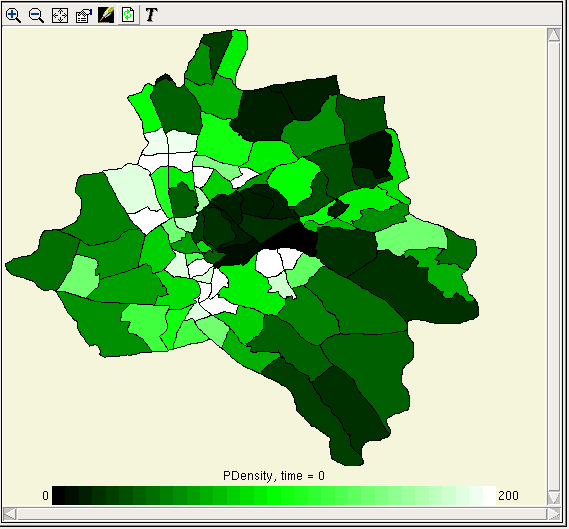
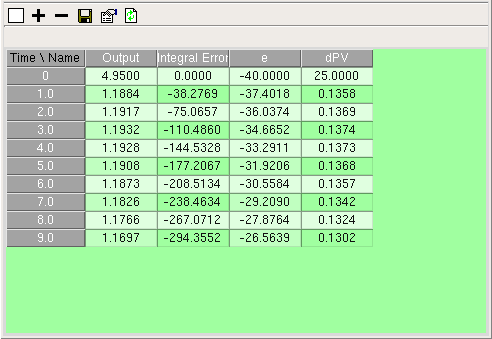
 Inspect model variable
Inspect model variable ) which will refresh the displayed data with the current values from the model.
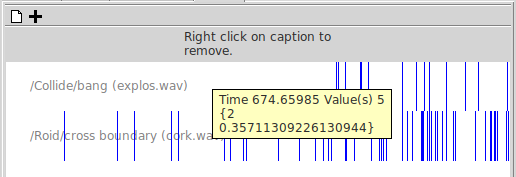
) which will refresh the displayed data with the current values from the model. ) and select a file name. Then start the model executing. The values displayed in the snapshot window will not change, but after each display interval the current values will be appended to the file. In this case the indices will be listed in rows at the top of the file, outermost first, with the actual data items appearing below them, one row for each time point. The times themselves will appear in the leftmost column. To stop logging, hit the log button again.
) and select a file name. Then start the model executing. The values displayed in the snapshot window will not change, but after each display interval the current values will be appended to the file. In this case the indices will be listed in rows at the top of the file, outermost first, with the actual data items appearing below them, one row for each time point. The times themselves will appear in the leftmost column. To stop logging, hit the log button again. Fixed parameter
Fixed parameter Variable parameter
Variable parameter paper roll behind its usual appearance.
paper roll behind its usual appearance. properties button in the toolbar of the model run environment.
properties button in the toolbar of the model run environment.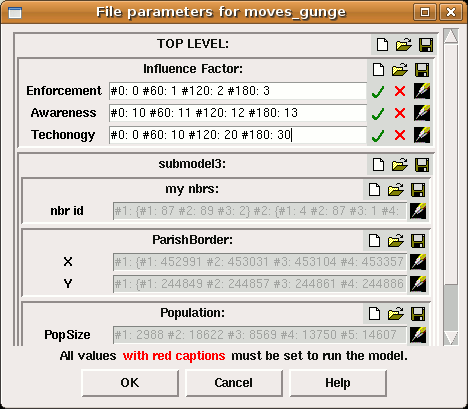
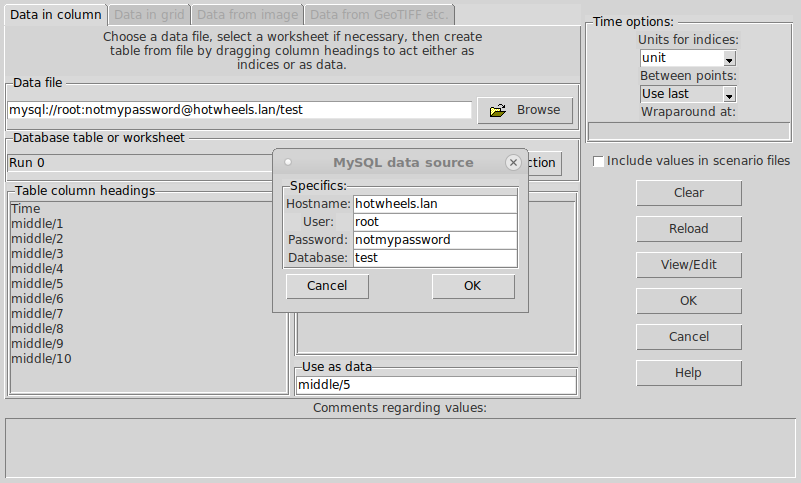

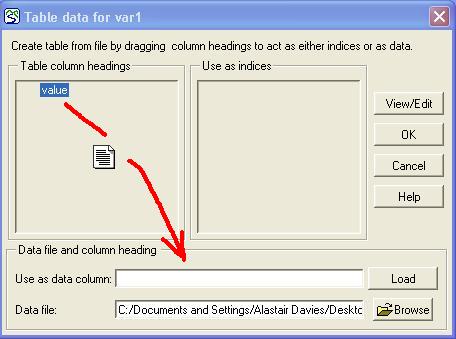



 ‘Default case’ heading, indicating that these values correspond to the ‘real world’. There is also an
‘Default case’ heading, indicating that these values correspond to the ‘real world’. There is also an  ‘Experimental conditions’ heading, with an empty tree. This tree can be built up by adding experimental cases.
‘Experimental conditions’ heading, with an empty tree. This tree can be built up by adding experimental cases. variable parameter, in which case the data for it will be an alternating list of time points and values to apply at those times. Once you have selected a parameter, an entry field for it will appear under the Experimental conditions header, as part of a new tree.
variable parameter, in which case the data for it will be an alternating list of time points and values to apply at those times. Once you have selected a parameter, an entry field for it will appear under the Experimental conditions header, as part of a new tree. List for parameter
List for parameter Multi-factor case
Multi-factor case Set of permutations
Set of permutations


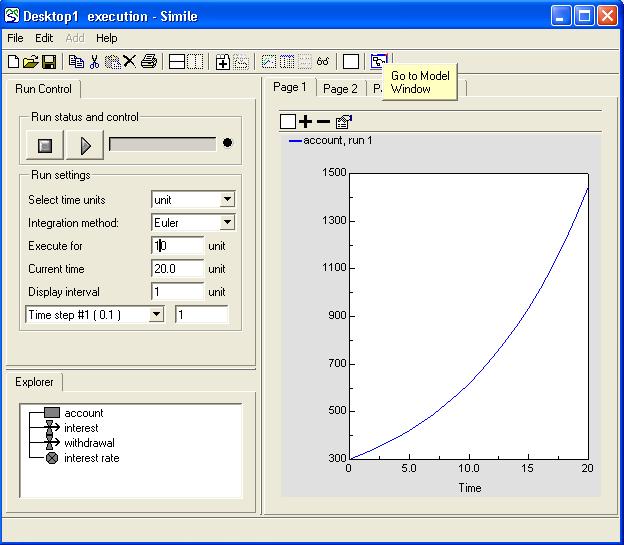
 "Go to model window" and
"Go to model window" and  "Go to run control" toolbar buttons to move back and forth between the pair.
"Go to run control" toolbar buttons to move back and forth between the pair.